 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Thought Prompt Distillation for Multimodal Named Entity and Multimodal Relation Extraction
Jun 29, 2023Multimodal Named Entity Recognition (MNER) and Multimodal Relation Extraction (MRE) necessitate the fundamental reasoning capacity for intricate linguistic and multimodal comprehension. In this study, we explore distilling the reasoning ability of large language models (LLMs) into a more compact student model by generating a \textit{chain of thought} (CoT) -- a sequence of intermediate reasoning steps. Specifically, we commence by exemplifying the elicitation of such reasoning ability from LLMs through CoT prompts covering multi-grain (noun, sentence, multimodality) and data-augmentation (style, entity, image) dimensions. Subsequently, we present a novel conditional prompt distillation method to assimilate the commonsense reasoning ability from LLMs, thereby enhancing the utility of the student model in addressing text-only inputs without the requisite addition of image and CoT knowledge. Extensive experiments reveal that our approach attains state-of-the-art accuracy and manifests a plethora of advantages concerning interpretability, data efficiency, and cross-domain generalization on MNER and MRE datasets.
Homogeneous and Heterogeneous Relational Graph for Visible-infrared Person Re-identification
Sep 18, 2021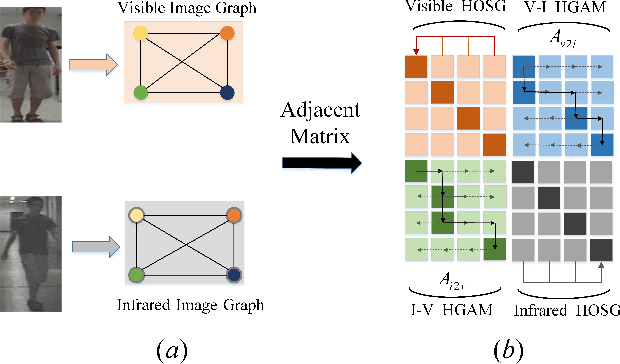
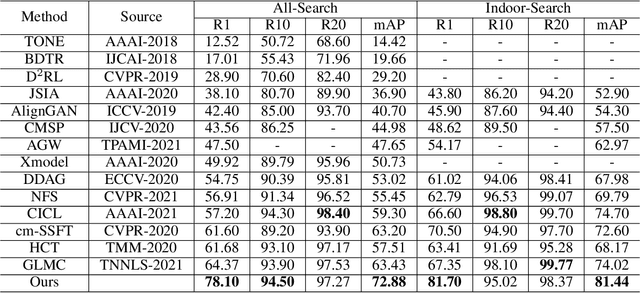
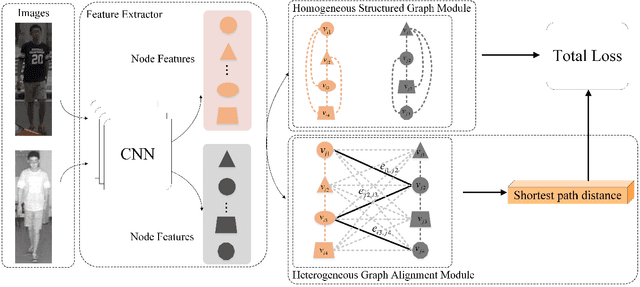
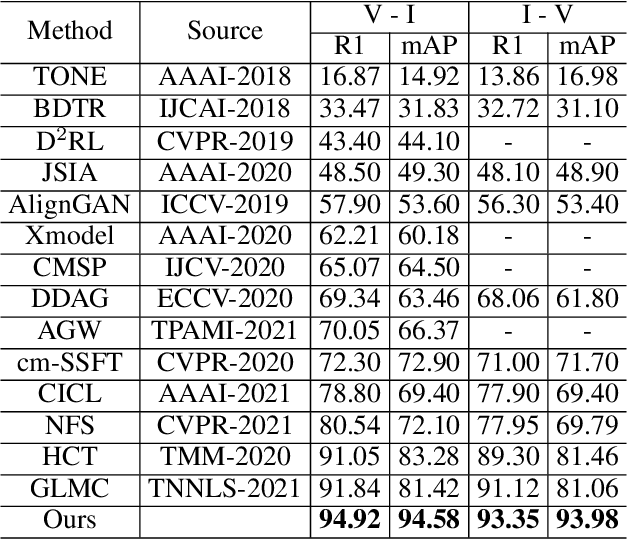
Visible-infrared person re-identification (VI Re-ID) aims to match person images between the visible and infrared modalities. Existing VI Re-ID methods mainly focus on extracting homogeneous structural relationships from a single image, while ignoring the heterogeneous correlation between cross-modality images. The homogenous and heterogeneous structured relationships are crucial to learning effective identity representation and cross-modality matching. In this paper, we separately model the homogenous structural relationship by a modality-specific graph within individual modality and then mine the heterogeneous structural correlation in these two modality-specific graphs. First, the homogeneous structured graph (HOSG) mines one-vs.-rest relation between an arbitrary node (local feature) and all the rest nodes within a visible or infrared image to learn effective identity representation. Second, to find cross-modality identity-consistent correspondence, the heterogeneous graph alignment module (HGAM) further measures the relational edge strength by route search between two-modality local node features. Third, we propose the cross-modality cross-correlation (CMCC) loss to extract the modality invariance in heterogeneous global graph representation. CMCC computes the mutual information between modalities and expels semantic redundancy. Extensive experiments on SYSU-MM01 and RegDB datasets demonstrate that our method outperforms state-of-the-arts with a gain of 13.73\% and 9.45\% Rank1/mAP. The code is available at https://github.com/fegnyujian/Homogeneous-and-Heterogeneous-Relational-Graph.